library(dplyr)
library(broom)
library(fixest)
library(ggplot2)第12章のRコード
第12章 操作変数法
パッケージの読み込み
12.2 パネルデータ回帰分析
12.2.3 Rによる固定効果モデルの推定
prefdata <- readr::read_csv("prefecture.csv")
prefdata %>%
print(n = 4)# A tibble: 1,081 × 4
pref year suicide unemp
<chr> <dbl> <dbl> <dbl>
1 北海道 1997 19.6 3.7
2 青森 1997 26.5 3.9
3 岩手 1997 25.8 2.4
4 宮城 1997 18.6 3.1
# ℹ 1,077 more rowsprefdata %>%
lm(suicide ~ -1 + unemp + pref,
data = .) %>%
tidy() %>%
select(term, estimate) %>%
filter(term == "unemp")# A tibble: 1 × 2
term estimate
<chr> <dbl>
1 unemp 3.07prefdata %>%
group_by(pref) %>%
mutate(suicidebar = mean(suicide),
unempbar = mean(unemp),
suicide2 = suicide - suicidebar,
unemp2 = unemp - unempbar) %>%
lm(suicide2 ~ -1 + unemp2,
data = .) %>%
tidy() %>%
select(term, estimate)# A tibble: 1 × 2
term estimate
<chr> <dbl>
1 unemp2 3.07prefdata %>%
feols(suicide ~ unemp | pref + year)OLS estimation, Dep. Var.: suicide
Observations: 1,081
Fixed-effects: pref: 47, year: 23
Standard-errors: Clustered (pref)
Estimate Std. Error t value Pr(>|t|)
unemp 0.770868 0.298724 2.58054 0.013121 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 1.76097 Adj. R2: 0.8622
Within R2: 0.022751prefdata %>%
feols(suicide ~ unemp | pref + year) %>%
fixef()$pref
三重 京都 佐賀 兵庫 北海道 千葉 和歌山 埼玉
15.45397 14.13019 17.11202 15.45899 17.49214 14.90050 19.09119 15.04125
大分 大阪 奈良 宮城 宮崎 富山 山口 山形
17.06491 15.84755 13.11925 16.34422 22.15730 20.04691 18.36547 20.79473
山梨 岐阜 岡山 岩手 島根 広島 徳島 愛媛
18.33060 17.04139 14.04390 24.71817 22.27627 15.54064 13.88266 17.44879
愛知 新潟 東京 栃木 沖縄 滋賀 熊本 石川
14.07081 23.07379 14.77983 18.14798 15.48147 14.92670 16.94297 15.64029
神奈川 福井 福岡 福島 秋田 群馬 茨城 長崎
13.67033 16.38198 16.29855 18.89778 27.86661 18.77796 16.90630 16.83410
長野 青森 静岡 香川 高知 鳥取 鹿児島
17.49636 22.45245 15.31457 14.55124 19.28600 17.42461 18.57975
$year
1997 1998 1999 2000 2001 2002 2003
0.0000000 5.5833995 4.5654306 3.7648943 2.9584970 3.5622088 5.5267073
2004 2005 2006 2007 2008 2009 2010
4.3136910 4.7456166 4.7956255 5.2002432 4.6308207 4.2217904 2.8488754
2011 2012 2013 2014 2015 2016 2017
2.4818250 0.8309494 0.8858371 -0.2012504 -0.9517742 -2.1754777 -2.3757769
2018 2019
-2.6837893 -2.8346302
attr(,"class")
[1] "fixest.fixef" "list"
attr(,"references")
pref year
0 1
attr(,"exponential")
[1] FALSEprefdata %>%
mutate(year = as.factor(year)) %>%
lm(suicide ~ -1 + unemp + pref + year,
data = .)
Call:
lm(formula = suicide ~ -1 + unemp + pref + year, data = .)
Coefficients:
unemp pref三重 pref京都 pref佐賀 pref兵庫 pref北海道
0.7709 15.4540 14.1302 17.1120 15.4590 17.4921
pref千葉 pref和歌山 pref埼玉 pref大分 pref大阪 pref奈良
14.9005 19.0912 15.0413 17.0649 15.8475 13.1192
pref宮城 pref宮崎 pref富山 pref山口 pref山形 pref山梨
16.3442 22.1573 20.0469 18.3655 20.7947 18.3306
pref岐阜 pref岡山 pref岩手 pref島根 pref広島 pref徳島
17.0414 14.0439 24.7182 22.2763 15.5406 13.8827
pref愛媛 pref愛知 pref新潟 pref東京 pref栃木 pref沖縄
17.4488 14.0708 23.0738 14.7798 18.1480 15.4815
pref滋賀 pref熊本 pref石川 pref神奈川 pref福井 pref福岡
14.9267 16.9430 15.6403 13.6703 16.3820 16.2986
pref福島 pref秋田 pref群馬 pref茨城 pref長崎 pref長野
18.8978 27.8666 18.7780 16.9063 16.8341 17.4964
pref青森 pref静岡 pref香川 pref高知 pref鳥取 pref鹿児島
22.4524 15.3146 14.5512 19.2860 17.4246 18.5798
year1998 year1999 year2000 year2001 year2002 year2003
5.5834 4.5654 3.7649 2.9585 3.5622 5.5267
year2004 year2005 year2006 year2007 year2008 year2009
4.3137 4.7456 4.7956 5.2002 4.6308 4.2218
year2010 year2011 year2012 year2013 year2014 year2015
2.8489 2.4818 0.8309 0.8858 -0.2013 -0.9518
year2016 year2017 year2018 year2019
-2.1755 -2.3758 -2.6838 -2.8346 POLS <- prefdata %>%
feols(suicide ~ unemp | year)
TWFE <- prefdata %>%
feols(suicide ~ unemp | pref + year)
etable(POLS, TWFE) POLS TWFE
Dependent Var.: suicide suicide
unemp 0.5133** (0.1461) 0.7709* (0.2987)
Fixed-Effects: ----------------- ----------------
year Yes Yes
pref No Yes
_______________ _________________ ________________
S.E.: Clustered by: year by: pref
Observations 1,081 1,081
R2 0.48386 0.87100
Within R2 0.01461 0.02275
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 112.3 差の差分析
12.3.3 平行トレンド仮定の検証
set.seed(2022)
n <- 80 # 標本サイズ
ID <- rep(1:n, each = 3) # 個人ID
t <- rep(c(0,1,2), times = n) # 時点
D <- rep(c(1,0), each = 3*(n/2)) # トリートメント
phi <- rep(runif(n), each = 3) # 個人効果
sim <- function(){
Y <- phi + D * t + rnorm(3 * n)
t0D <- D * (t == 0)
t2D <- D * (t == 2)
df <- tibble(ID, Y, D, t, t0D, t2D)
reg <- feols(Y ~ t0D + t2D | ID + t, data = df)
pval <- reg$coeftable[, 4]
c(pval[1] < 0.1, pval[2] < 0.1)
}
nrep <- 500
res <- matrix(0, nrep, 2)
for(i in 1:nrep){
res[i, ] <- sim()
}
sum(res[, 1] == FALSE & res[, 2] == FALSE)[1] 0sum(res[, 1] == FALSE & res[, 2] == TRUE)[1] 28図 12.5
set.seed(2022)
n <- 80 # 標本サイズ
ID <- rep(1:n, each = 3) # 個人ID
t <- rep(c(0,1,2), times = n) # 時点
D <- rep(c(1,0), each = 3*(n/2)) # トリートメント
phi <- rep(runif(n), each = 3) # 個人効果
sim <- function(){
Y <- phi + D * t + rnorm(3 * n)
X0 <- D * (t == 0)
X2 <- D * (t == 2)
df <- tibble(ID, Y, D, t, X0, X2)
reg <- feols(Y ~ X0 + X2 | ID + t, data = df)
pval <- reg$coeftable[, 4]
Y0mean0 <- mean(Y[D == 0 & t == 0])
Y1mean0 <- mean(Y[D == 1 & t == 0])
dY0 <- Y1mean0 - Y0mean0
Y0mean1 <- mean(Y[D == 0 & t == 1])
Y1mean1 <- mean(Y[D == 1 & t == 1])
dY1 <- Y1mean1 - Y0mean1
Y0mean2 <- mean(Y[D == 0 & t == 2])
Y1mean2 <- mean(Y[D == 1 & t == 2])
dY2 <- Y1mean2 - Y0mean2
c(pval[1] < 0.1, pval[2] < 0.1, dY0, dY1, dY2)
}
nrep <- 500
res <- matrix(0, nrep, 6)
for(i in 1:nrep){
res[i, 1:5] <- sim()
res[i, 6] <- i
}
sum(res[, 1] == FALSE & res[, 2] == FALSE)[1] 0sum(res[, 1] == FALSE & res[, 2] == TRUE)[1] 28df <- rbind(res[, c(1, 2, 3, 6)],
res[, c(1, 2, 4, 6)],
res[, c(1, 2, 5, 6)])
df <- as.data.frame(df)
df$t <- rep(0:2, each = 500)
colnames(df) <- c("presig", "postsig", "mean", "trial", "period")
df %>%
filter(presig == 0 & postsig == 1) %>%
group_by(trial) %>%
ggplot(aes(x = period, y = mean, line = as.factor(trial))) +
geom_abline(slope = 1, intercept = 0, size = 2) +
geom_line(linetype = "dashed", colour = "grey") +
xlab("時点") +
ylab(expression(paste(Delta, widehat(Y)[t]))) +
theme_gray(base_family = "HiraKakuPro-W3")Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.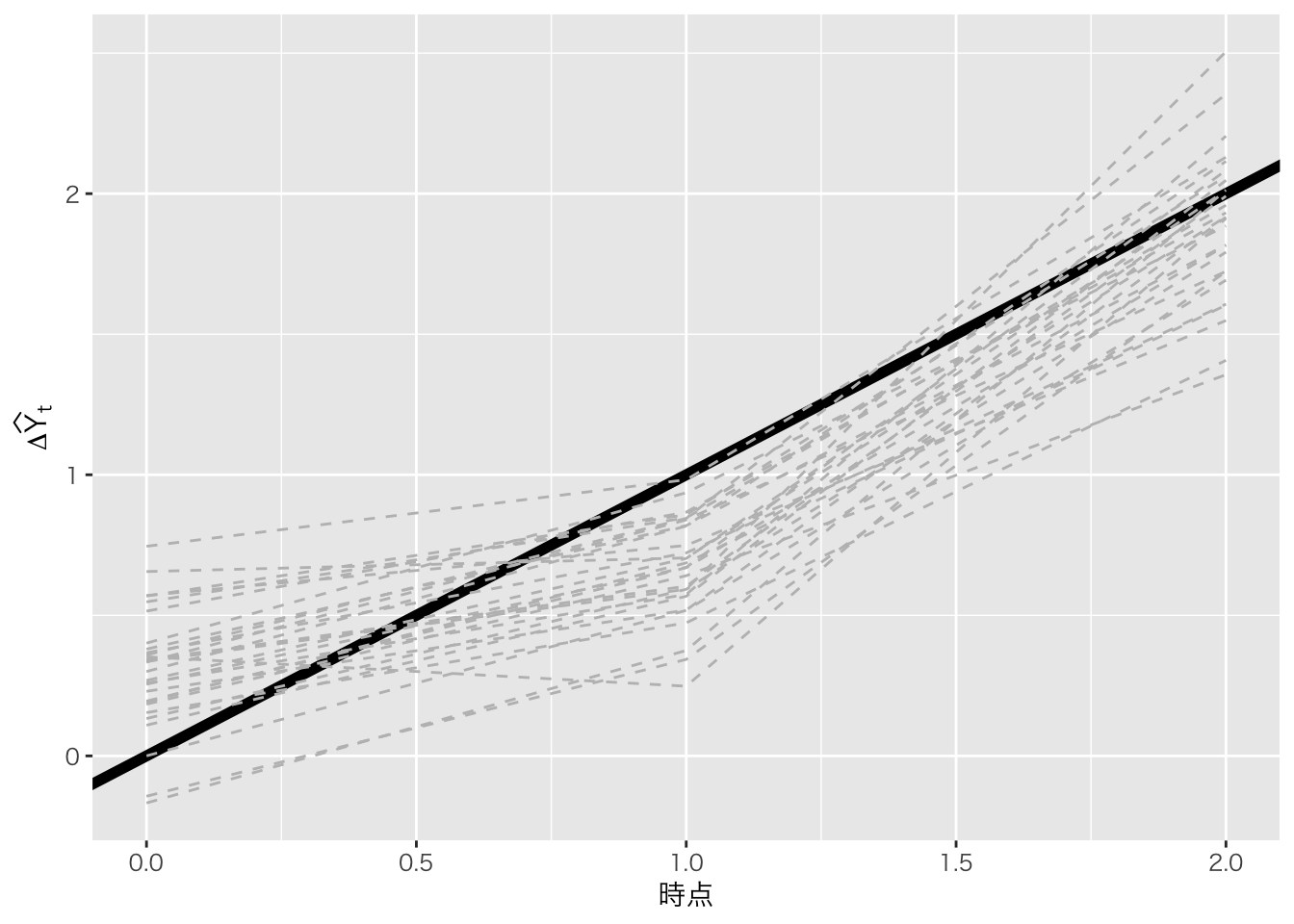
Rによるデータ演習
mwdata <- readr::read_csv("minimum_wage.csv")
mwdata %>%
print(n = 4)# A tibble: 714 × 5
store_id post emp price nj
<dbl> <dbl> <dbl> <dbl> <dbl>
1 6 0 5 4.72 1
2 14 0 16 4.4 1
3 26 0 41.5 2.95 1
4 27 0 13 4.25 1
# ℹ 710 more rowsmwdata %>%
feols(emp ~ post:nj | store_id + post)OLS estimation, Dep. Var.: emp
Observations: 714
Fixed-effects: store_id: 357, post: 2
Standard-errors: Clustered (store_id)
Estimate Std. Error t value Pr(>|t|)
post:nj 2.32583 1.45228 1.6015 0.11015
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 4.3831 Adj. R2: 0.572598
Within R2: 0.010618mwdata %>%
group_by(nj) %>%
summarise(mean_post = mean(emp[post == 1]),
mean_pre = mean(emp[post == 0])) %>%
mutate(diff = mean_post - mean_pre) %>%
summarise(did = diff[nj == 1] - diff[nj == 0])# A tibble: 1 × 1
did
<dbl>
1 2.33mwdata %>%
filter(is.na(price)) %>%
print(n = 4)# A tibble: 42 × 5
store_id post emp price nj
<dbl> <dbl> <dbl> <dbl> <dbl>
1 234 0 8 NA 1
2 324 0 48 NA 1
3 326 0 45.5 NA 1
4 375 0 34 NA 1
# ℹ 38 more rowsmwdata %>%
tidyr::drop_na(price) %>%
group_by(store_id) %>%
filter(n() == 2)# A tibble: 634 × 5
# Groups: store_id [317]
store_id post emp price nj
<dbl> <dbl> <dbl> <dbl> <dbl>
1 6 0 5 4.72 1
2 14 0 16 4.4 1
3 26 0 41.5 2.95 1
4 27 0 13 4.25 1
5 30 0 10 4.65 1
6 31 0 15 4.65 1
7 33 0 26 3.04 1
8 36 0 18 4.5 1
9 77 0 35 3.42 1
10 78 0 21 3.16 1
# ℹ 624 more rowsmwdata %>%
tidyr::drop_na(price) %>%
group_by(store_id) %>%
filter(n() == 2) %>%
feols(log(price) ~ post:nj | store_id + post)OLS estimation, Dep. Var.: log(price)
Observations: 634
Fixed-effects: store_id: 317, post: 2
Standard-errors: Clustered (store_id)
Estimate Std. Error t value Pr(>|t|)
post:nj 0.032525 0.014186 2.2928 0.022516 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 0.050409 Adj. R2: 0.84979
Within R2: 0.015916mwdata %>%
tidyr::drop_na(price) %>%
group_by(store_id) %>%
filter(n() == 2) %>%
filter(post == 1) %>%
feols(log(price) ~ nj)OLS estimation, Dep. Var.: log(price)
Observations: 317
Standard-errors: IID
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.096503 0.022655 48.40011 < 2.2e-16 ***
nj 0.129299 0.025210 5.12888 5.1022e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 0.176382 Adj. R2: 0.074143