set.seed(2022)第2章のRコード
第2章 統計の基礎知識
乱数の設定
2.1 母集団と標本
rnorm(100, 50, 10) [1] 59.00142 38.26654 41.02515 35.55499 46.68986 20.99371 39.40744 52.77955
[9] 57.49486 52.41583 60.06186 48.14854 40.18173 50.92908 49.47216 49.19672
[17] 43.45896 40.49316 60.19562 58.59046 53.64461 53.83651 61.13406 62.11510
[25] 46.51675 41.40447 56.50027 53.28059 44.82053 47.61018 51.17779 58.31518
[33] 34.41081 47.79481 41.82806 60.76677 60.79664 51.42128 51.56980 48.31280
[41] 47.30962 58.07768 38.75283 35.69212 50.60357 42.07018 53.40276 47.40531
[49] 36.95151 53.68173 66.93190 59.95837 51.86752 62.38337 53.09373 56.35718
[57] 50.23183 61.77864 45.46453 54.15928 36.61558 37.08025 46.90926 51.56512
[65] 41.66083 49.75451 38.62648 60.72054 73.14499 54.22973 48.63061 63.28397
[73] 54.36536 50.66429 63.04660 47.90740 60.18253 63.66035 64.76696 58.87307
[81] 39.84091 68.70869 60.76198 39.25592 28.04424 55.34545 63.43733 63.85004
[89] 77.46927 49.54055 57.43085 52.60425 54.28282 46.31741 78.87423 43.92927
[97] 31.20801 57.18357 52.51426 54.67023curve(dnorm(x, 50, 10), 0, 100, xlab = "", ylab = "")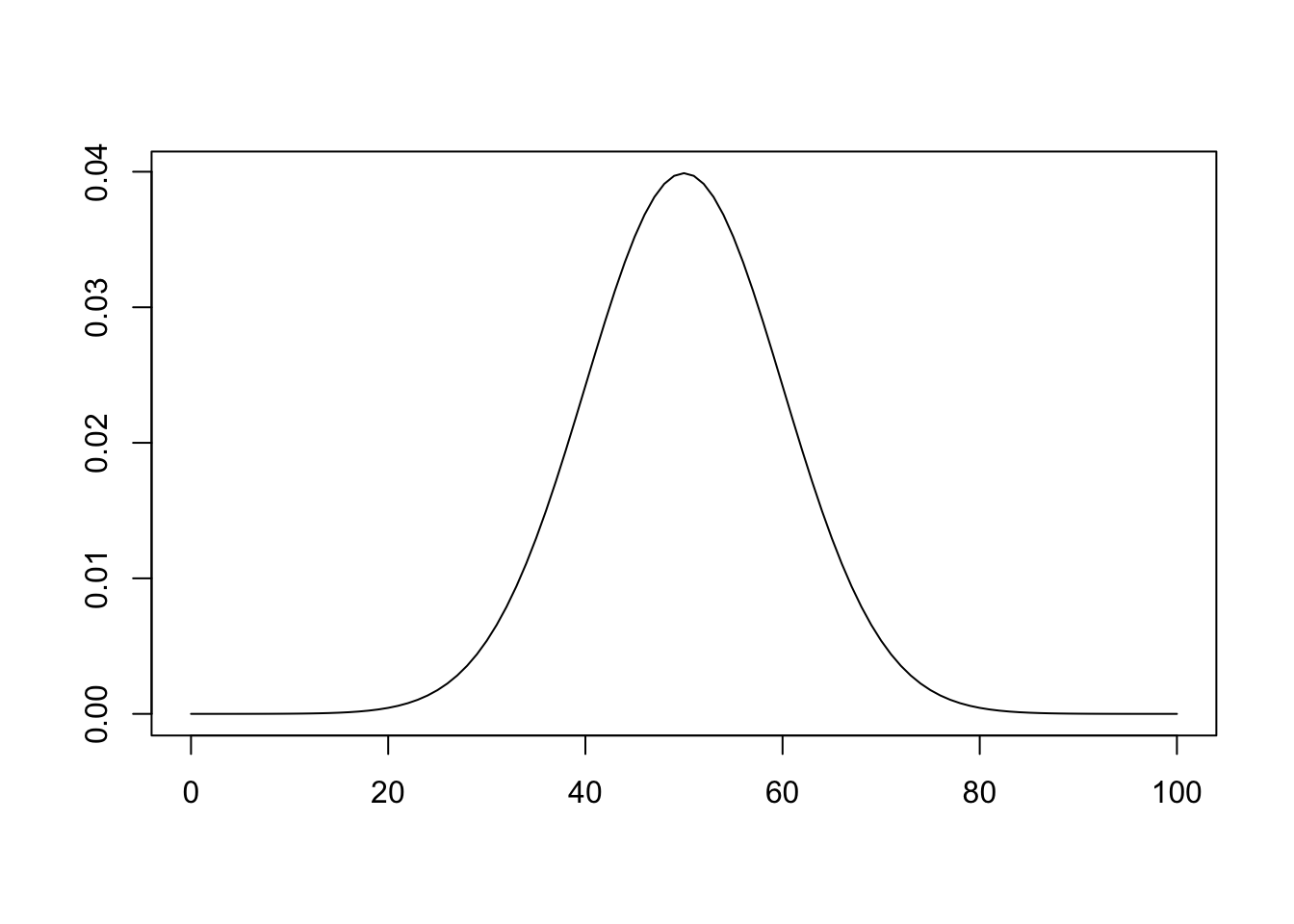
pnorm(60, 50, 10)[1] 0.84134472.2 無作為抽出
rnorm(100, 50, 10) [1] 47.82112 37.82352 42.45921 51.91230 60.47283 60.89828 56.95474 44.75631
[9] 52.64016 62.41200 56.43297 40.03237 29.97702 45.24161 50.44180 36.18865
[17] 52.47520 52.24190 58.61479 40.73238 46.79557 56.73025 37.34370 44.81479
[25] 61.22494 46.84022 32.41701 62.37253 33.36048 68.55734 60.57997 50.37269
[33] 50.04605 30.56166 34.30377 47.26703 54.68854 60.32539 35.81604 49.12122
[41] 65.78631 52.44625 64.97093 59.15906 53.20841 55.62724 55.39295 39.26595
[49] 31.16839 59.11390 50.49596 37.64345 37.36248 38.57135 56.54412 43.23181
[57] 39.26090 40.24342 38.73725 30.30687 44.18011 32.37493 44.72174 36.25672
[65] 30.66287 59.79783 35.04310 67.00810 35.98974 45.15537 37.83821 51.04771
[73] 47.57463 35.84219 39.50540 52.69057 45.21284 47.00552 60.38149 60.28925
[81] 30.28325 37.16670 50.48581 62.10631 45.15329 42.06690 51.72414 61.05213
[89] 57.40876 47.58553 56.14957 63.82546 44.16797 48.02070 43.96771 39.11352
[97] 51.83915 63.07136 48.31717 53.43841Z <- rnorm(100, 50, 10)
Z [1] 53.76475 48.05460 28.84664 40.86933 53.49709 54.05577 55.05326 32.08133
[9] 43.38511 46.27727 51.58661 43.21588 50.82489 62.43740 58.80496 55.43959
[17] 42.09095 54.27145 59.51114 58.20117 31.89054 47.20086 56.71068 65.96973
[25] 42.74268 59.60575 59.56440 62.65848 47.63044 34.79886 53.39553 63.95974
[33] 38.13938 45.95528 47.12894 59.42586 39.45261 43.42722 45.85711 54.53967
[41] 44.46046 53.53869 51.48286 53.76512 65.06987 40.72705 44.12859 74.58926
[49] 56.73742 53.34424 66.09042 38.84601 50.10130 39.47642 54.33923 56.58090
[57] 35.59927 54.73361 41.94148 42.14534 38.64649 40.88575 50.89966 47.63905
[65] 66.27579 55.05201 50.37437 53.65165 36.05399 56.35135 45.22247 41.80026
[73] 62.52384 36.81650 55.44261 48.13103 56.15964 55.27988 52.34455 48.87702
[81] 36.83703 46.63232 54.78410 39.06088 62.61406 50.36015 68.81067 41.33545
[89] 40.05152 34.82766 49.59823 32.13462 59.56246 47.19504 45.88813 45.36570
[97] 25.45063 53.12886 42.08662 52.25465hist(Z)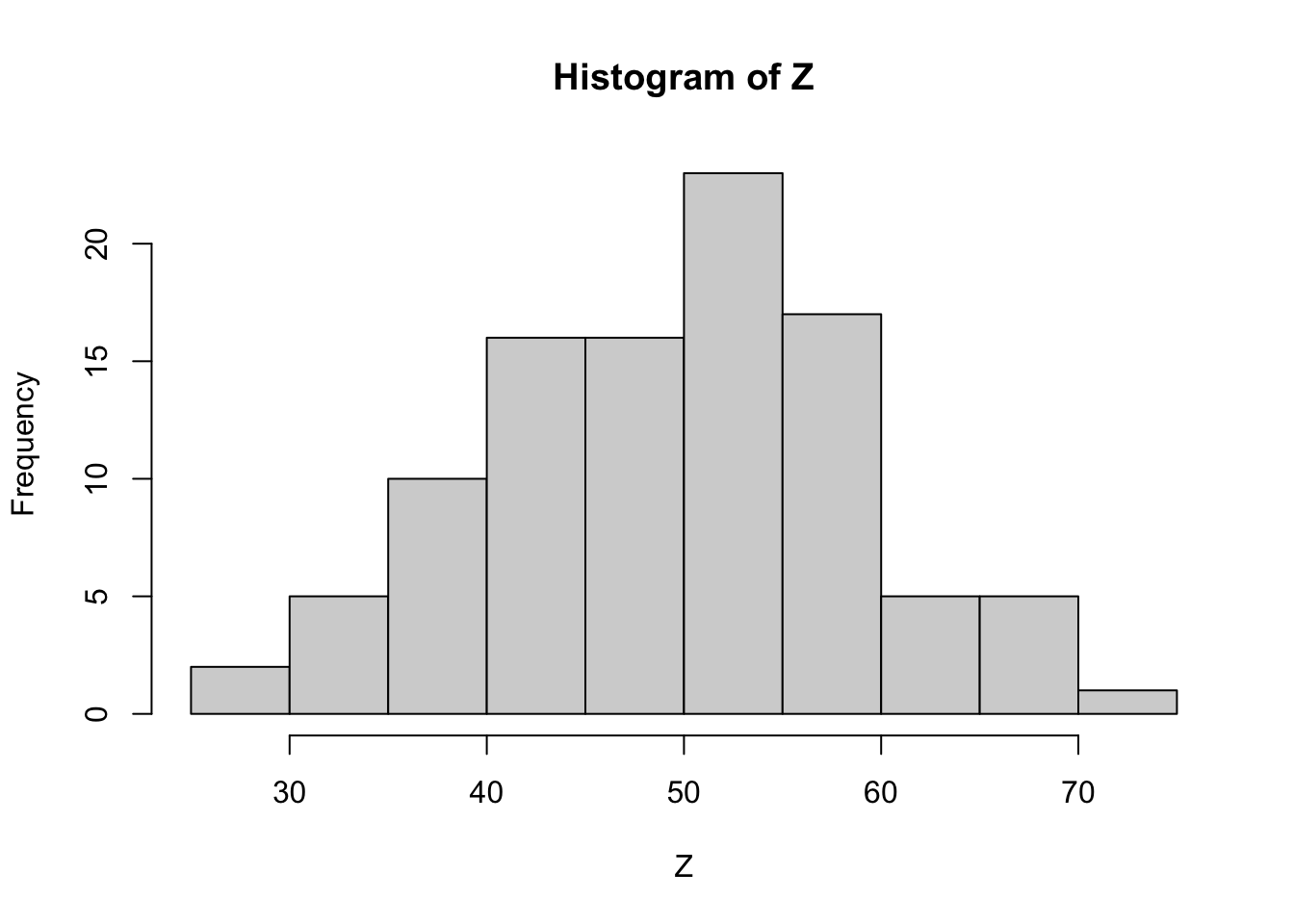
Z[1:10] [1] 53.76475 48.05460 28.84664 40.86933 53.49709 54.05577 55.05326 32.08133
[9] 43.38511 46.27727a <- c(5, 10, 100)Z[a][1] 53.49709 46.27727 52.25465Z[c(5, 10, 100)][1] 53.49709 46.27727 52.25465max(Z)[1] 74.58926which.max(Z)[1] 48min(Z)[1] 25.45063which.min(Z)[1] 97mean(Z)[1] 49.36427summary(Z) Min. 1st Qu. Median Mean 3rd Qu. Max.
25.45 42.09 50.23 49.36 55.32 74.59 1:10 [1] 1 2 3 4 5 6 7 8 9 10sample(1:10, 3)[1] 8 9 4sample(Z, 5)[1] 38.64649 44.46046 62.43740 39.47642 45.85711fruits <- c("ミカン", "バナナ", "リンゴ", "レモン", "モモ")
よくある間違い
fruits <- c(ミカン, バナナ, リンゴ, レモン, モモ)Error: object 'ミカン' not foundsample(fruits, 1)[1] "リンゴ"sample(fruits, 2)[1] "バナナ" "ミカン"coin <- c("Head", "Tail")
sample(coin, 5, replace = TRUE) # わかりづらい例なので再試行[1] "Tail" "Tail" "Tail" "Tail" "Tail"sample(coin, 5, replace = TRUE) # こちらの結果を掲載[1] "Tail" "Tail" "Tail" "Head" "Head"2.3 平均と大数の法則
mean(rnorm(100, 50, 10))[1] 49.95459S <- 1000
rec <- numeric(S)
for(i in 1:S){
rec[i] <- mean(rnorm(100, 50, 10))
}numeric(10) [1] 0 0 0 0 0 0 0 0 0 0summary(rec) Min. 1st Qu. Median Mean 3rd Qu. Max.
46.61 49.31 49.98 49.98 50.62 52.70 for(i in 1:S){
rec[i] <- mean(rnorm(10000, 50, 10))
}
summary(rec) Min. 1st Qu. Median Mean 3rd Qu. Max.
49.66 49.93 50.00 50.00 50.07 50.32 mean(sample(1:6, 10, replace = TRUE))[1] 4.1S <- 1000
rec <- numeric(S)
for(i in 1:S){
rec[i] <- mean(sample(1:6, 10, replace = TRUE))
}
summary(rec) Min. 1st Qu. Median Mean 3rd Qu. Max.
1.60 3.10 3.50 3.51 3.90 5.20 S <- 1000
rec <- numeric(S)
for(i in 1:S){
rec[i] <- mean(sample(1:6, 1000, replace = TRUE))
}
summary(rec) Min. 1st Qu. Median Mean 3rd Qu. Max.
3.336 3.460 3.498 3.496 3.533 3.673 S <- 1000
rec <- numeric(S)
for(i in 1:S){
rec[i] <- mean(sample(1:6, 10000, replace = TRUE))
}
summary(rec) Min. 1st Qu. Median Mean 3rd Qu. Max.
3.437 3.487 3.500 3.500 3.513 3.554 2.4 分散と標準偏差
x <- rnorm(1000, 50, 10)
var(x)[1] 101.8111sd(x)[1] 10.09015S <- 1000; n <- 1000
rec <- numeric(S)
for(i in 1:S){
rec[i] <- sd(rnorm(n, 50, 10))
}
summary(rec) Min. 1st Qu. Median Mean 3rd Qu. Max.
9.150 9.848 10.005 10.002 10.163 10.874 2.5 相関係数と共分散
set.seed(2022) # 乱数の再設定
x <- rnorm(100, 50, 10)
y <- rnorm(100, 50, 10)
plot(x, y)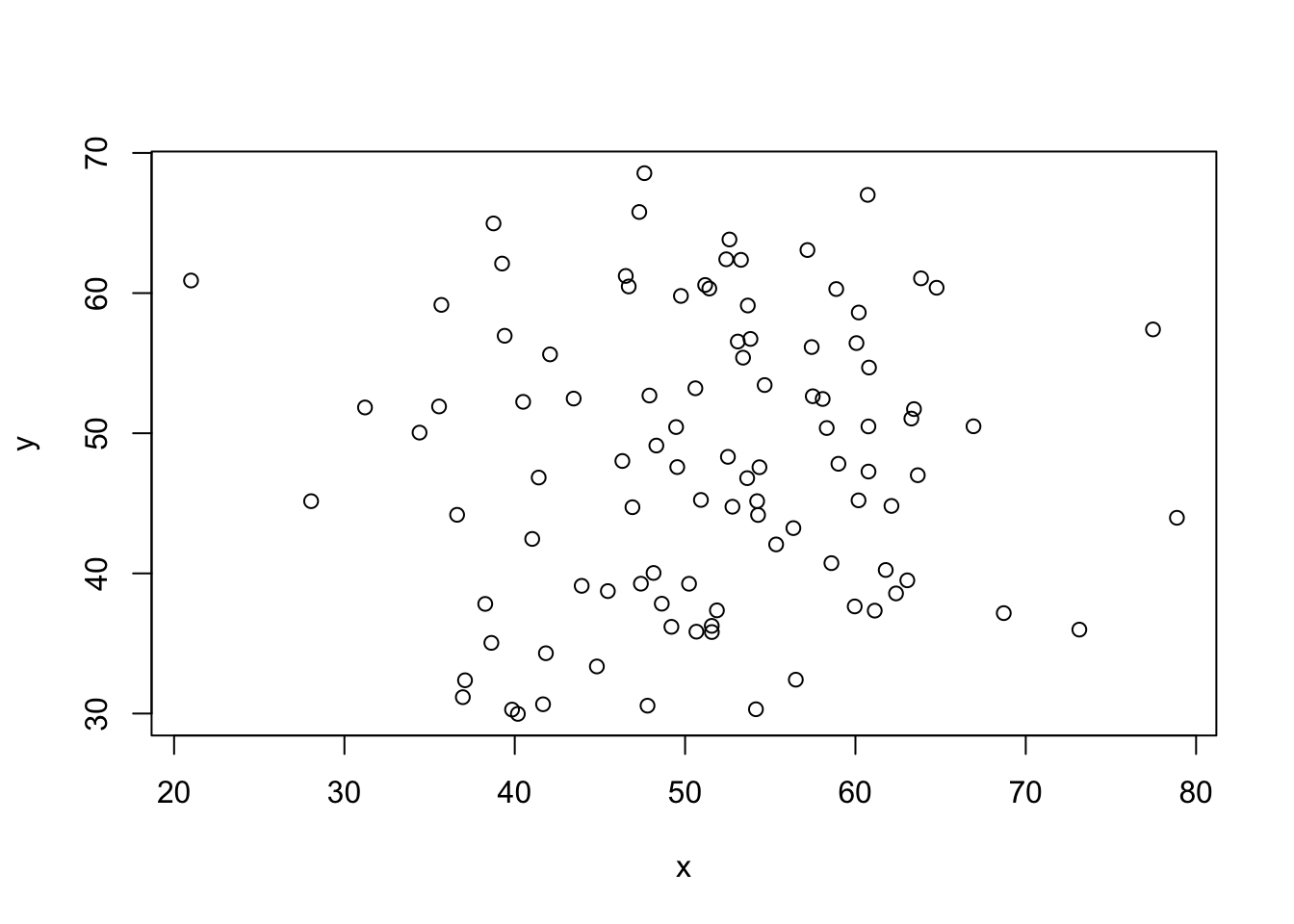
z <- (x + y) / 2
plot(x, z)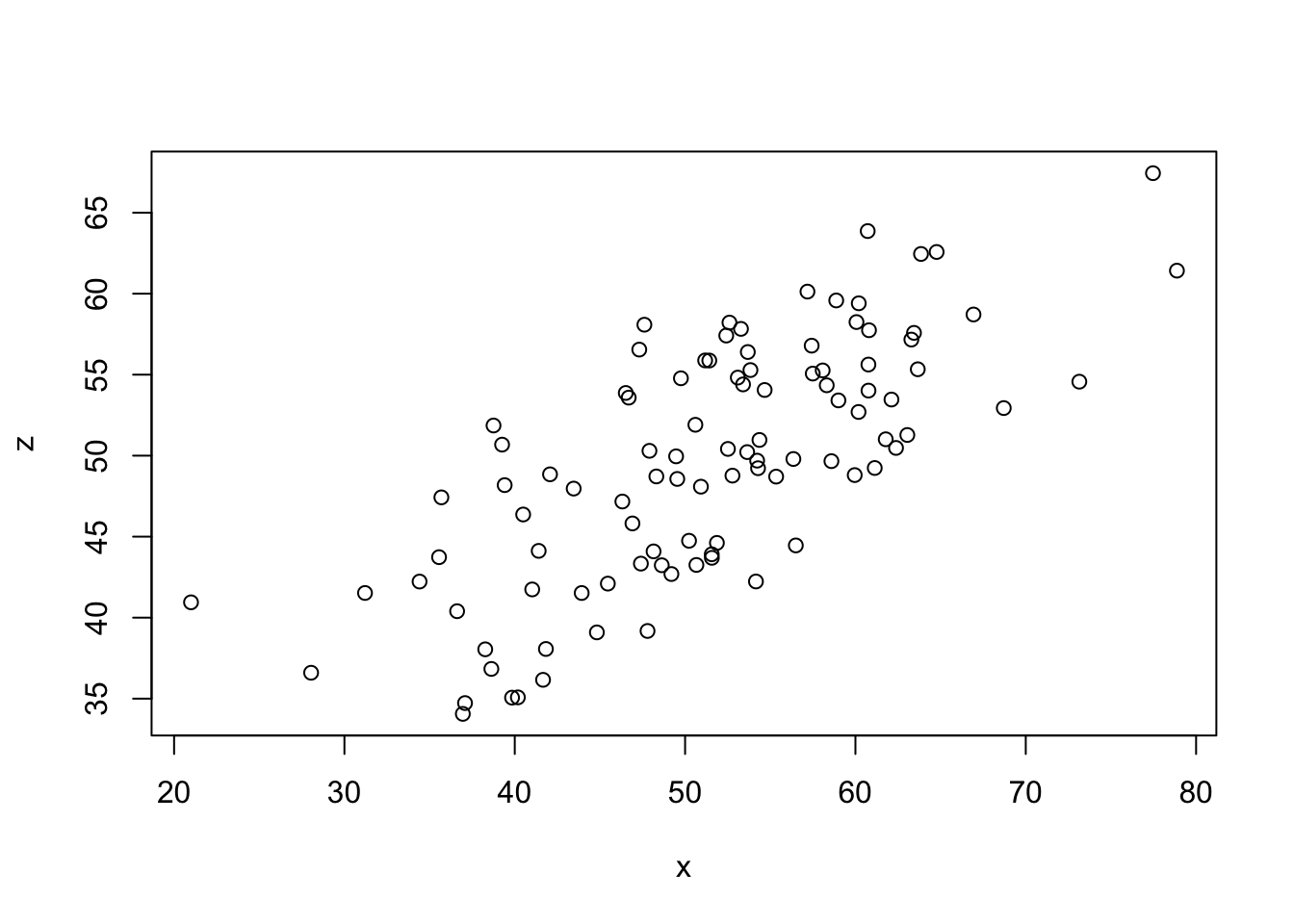
cor(x, y)[1] 0.05702949cor(x, z)[1] 0.7279044cov(x, y)[1] 5.917713