library(dplyr)
library(ggplot2)
library(broom)第8章のRコード
第8章 ランダム化実験
パッケージの読み込み
8.1 授業の出席率と成績:セレクションバイアス
8.1.1 因果関係?単なる相関関係?
classdata <- readr::read_csv("class_attendance.csv") # データの読み込み
classdata %>%
mutate(D = as.factor(D)) %>%
ggplot(aes(x = D, y = Y)) +
geom_point(position = position_jitter(width = 0.2, seed = 2022))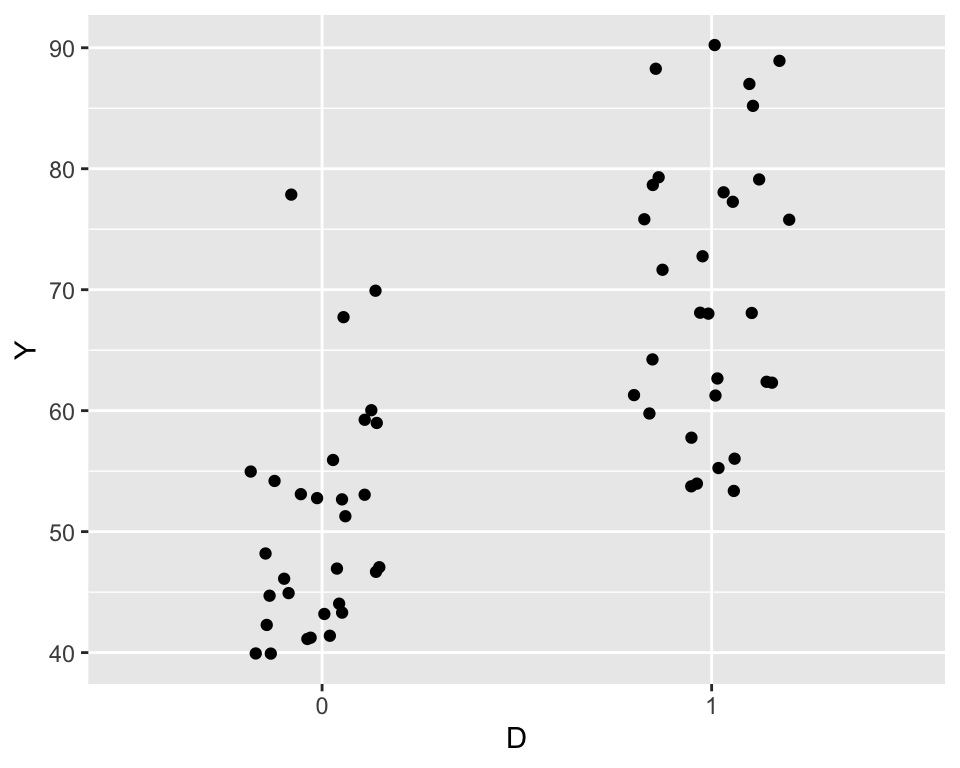
classdata %>%
mutate(" " = ifelse(D == 1, "D = 1 (出席率50%以上)", "D = 0 (出席率50%未満)")) %>%
group_by(` `) %>%
summarise(
学生数 = n(),
平均点 = round(mean(Y), 2),
最低点 = min(Y),
最高点 = max(Y)
) %>%
kableExtra::kbl() %>%
kableExtra::kable_classic_2()| 学生数 | 平均点 | 最低点 | 最高点 | |
|---|---|---|---|---|
| D = 0 (出席率50%未満) | 30 | 50.73 | 40 | 78 |
| D = 1 (出席率50%以上) | 30 | 69.83 | 53 | 90 |
8.2 ランダム化実験
8.2.2 セレクションバイアスの除去
classdata %>%
lm(Y ~ D,
data = .)
Call:
lm(formula = Y ~ D, data = .)
Coefficients:
(Intercept) D
50.73 19.10 Y1mean <- with(classdata, sum(D * Y) / sum(D))
Y0mean <- with(classdata, sum((1 - D) * Y) / sum(1 - D))
Y0mean # コントロールグループの平均値 = α[1] 50.73333Y1mean - Y0mean # 平均値の差 = β[1] 19.1classdata %>%
summarise(Y1mean = mean(Y[D == 1]),
Y0mean = mean(Y[D == 0]),
diff = Y1mean - Y0mean)# A tibble: 1 × 3
Y1mean Y0mean diff
<dbl> <dbl> <dbl>
1 69.8 50.7 19.1classdata %>%
lm(Y ~ D + motiv,
data = .) %>%
tidy()# A tibble: 3 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 41.2 2.80 14.7 4.60e-21
2 D 1.24 4.82 0.257 7.98e- 1
3 motiv 0.989 0.231 4.28 7.32e- 5