import pandas as pd
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
import numpy as np第10章のPythonコード
第10章 不連続回帰デザイン
モジュールのインポート
10.2 条件付平均トリートメント効果 \(\tau\) の推定
10.2.1 条件付期待値が線形の場合
examdata = pd.read_csv('exam_rdd.csv')
examdata.head()
examdata = examdata.assign(D = 1 * (examdata['Z'] < 60))
examdata = examdata.assign(Zc = examdata['Z'] - 60)
result = ols('Y ~ D + Zc + D:Zc', data = examdata).fit()
print(result.summary().tables[1])==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 60.0665 1.456 41.266 0.000 57.196 62.937
D 13.0402 2.034 6.412 0.000 9.030 17.051
Zc 0.8256 0.115 7.153 0.000 0.598 1.053
D:Zc -0.1650 0.167 -0.985 0.326 -0.495 0.165
==============================================================================10.2.2 条件付期待値が非線形の場合
h = 5
result = ols('Y ~ D', data = examdata.query('abs(Zc) <= @h')).fit()
print(result.summary().tables[1])
result = ols('Y ~ D * Zc', data = examdata.query('abs(Zc) <= @h')).fit()
print(result.summary().tables[1])==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 62.0736 1.612 38.514 0.000 58.861 65.287
D 10.6559 2.114 5.040 0.000 6.441 14.871
==============================================================================
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 63.6814 3.592 17.728 0.000 56.517 70.846
D 10.2933 4.689 2.195 0.031 0.941 19.645
Zc -0.6094 1.213 -0.502 0.617 -3.029 1.811
D:Zc 1.0566 1.548 0.682 0.497 -2.032 4.145
==============================================================================Rによるデータ演習
electdata = pd.read_csv('incumbency.csv')
electdata.head()| voteshare | margin | |
|---|---|---|
| 0 | 0.580962 | 0.104869 |
| 1 | 0.461059 | 0.139252 |
| 2 | 0.543411 | -0.073602 |
| 3 | 0.584580 | 0.086822 |
| 4 | 0.580286 | 0.399358 |
electdata = electdata.assign(D = 1 * (electdata['margin'] >= 0))
sns.set_theme(font='IPAexGothic')
sns.scatterplot(x = 'margin', y = 'voteshare', data = electdata)
plt.xlabel("前回の得票率 - 当落線")
plt.ylabel("得票率")
plt.show()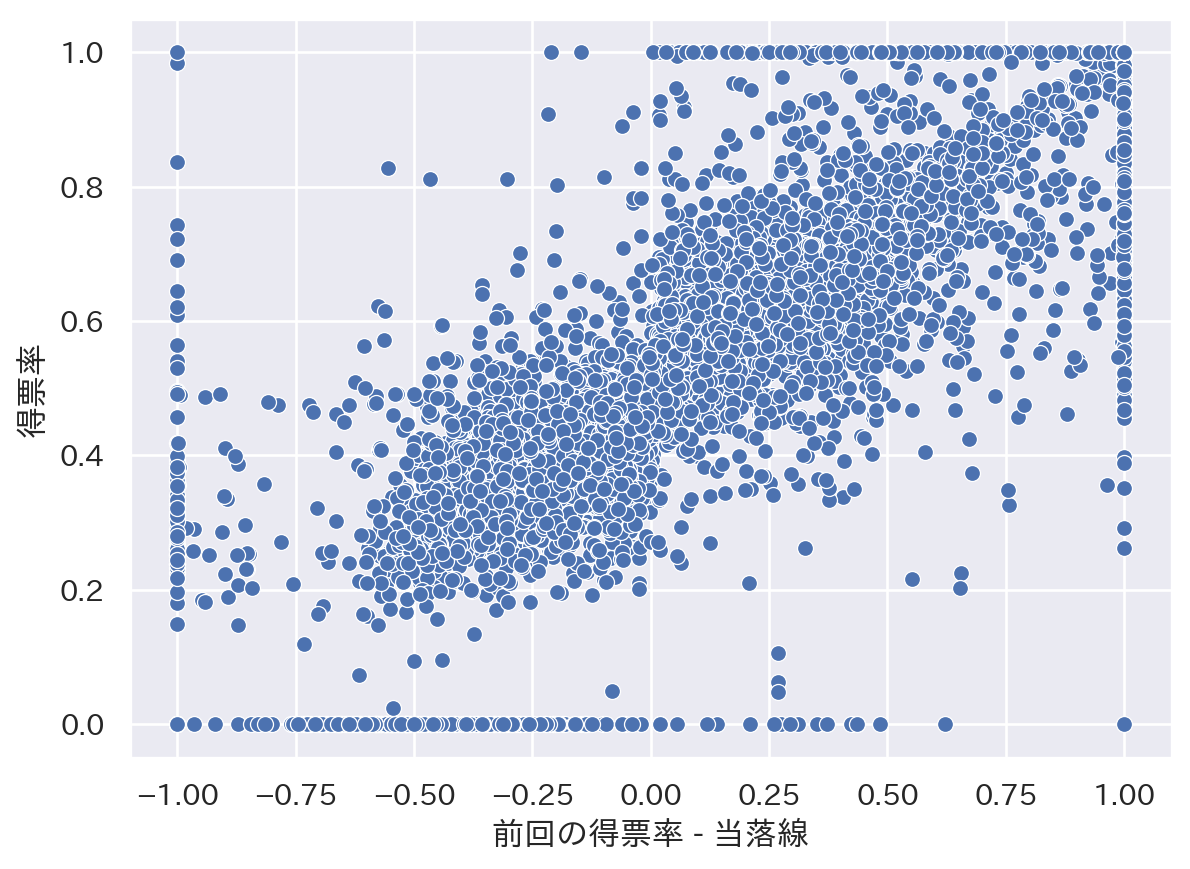
h = 0.25
result = ols('voteshare ~ D + margin + D:margin', data = electdata.query('abs(margin) <= @h')).fit()
print(result.summary().tables[1])
h = 0.05
result = ols('voteshare ~ D + margin + D:margin', data = electdata.query('abs(margin) <= @h')).fit()
print(result.summary().tables[1])==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.4509 0.006 74.291 0.000 0.439 0.463
D 0.0817 0.008 9.671 0.000 0.065 0.098
margin 0.3665 0.043 8.482 0.000 0.282 0.451
D:margin 0.0849 0.061 1.399 0.162 -0.034 0.204
==============================================================================
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.4692 0.014 33.727 0.000 0.442 0.497
D 0.0454 0.019 2.401 0.017 0.008 0.082
margin 0.9029 0.481 1.877 0.061 -0.042 1.848
D:margin 0.1100 0.645 0.171 0.865 -1.156 1.376
==============================================================================results = pd.DataFrame(columns = ['h', 'estimate', 'lci', 'uci'])
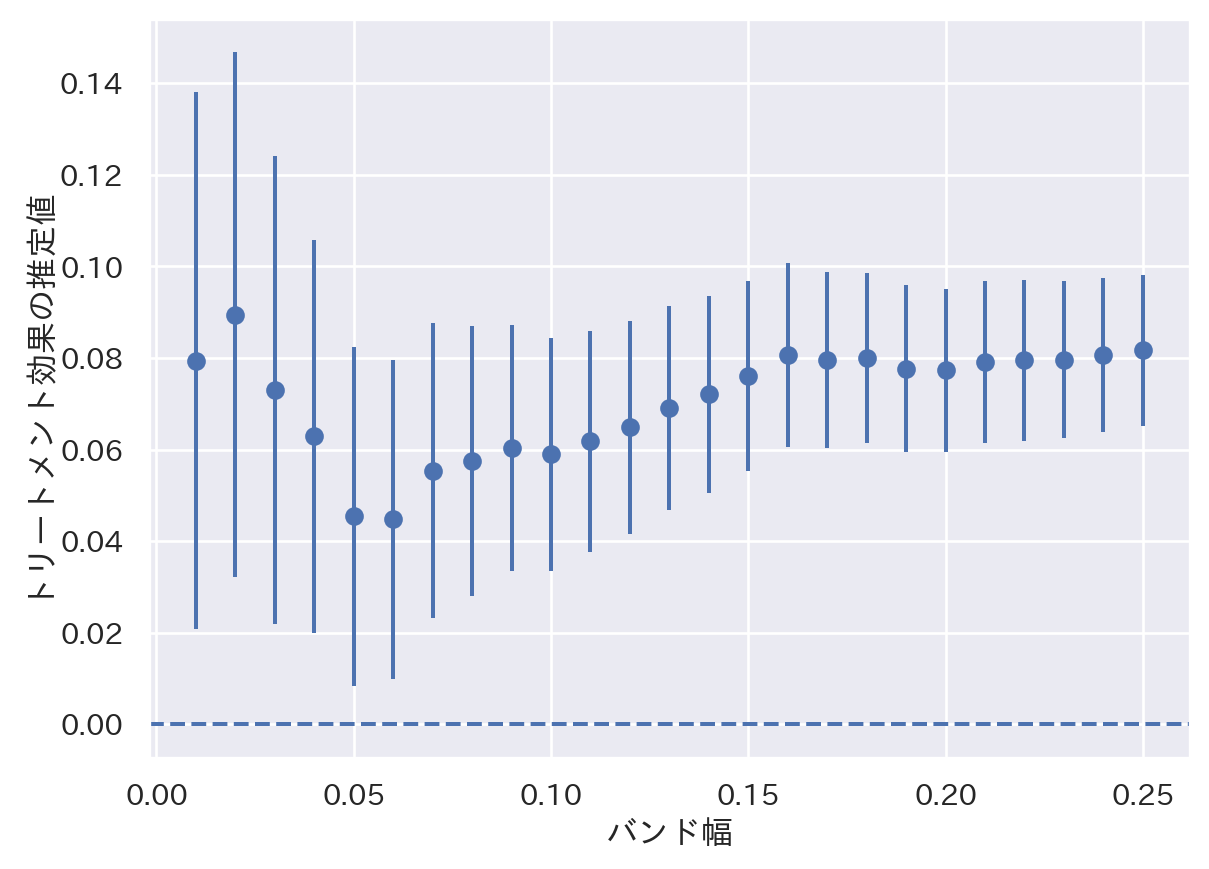
for h in np.linspace(0.01, 0.25, 25) :
result = ols('voteshare ~ D * margin', data = electdata.query('abs(margin) <= @h')).fit()
estimate = result.params[1]
lci = result.conf_int().values[1][0]
uci = result.conf_int().values[1][1]
foo = pd.DataFrame([[h, estimate, lci, uci]], columns = ['h', 'estimate', 'lci', 'uci'])
results = pd.concat([results, foo], ignore_index = True)results = results.assign(error = (results['uci'] - results['lci']) / 2)
plt.errorbar(x = 'h', y = 'estimate', yerr = 'error', fmt = 'o', data = results)
plt.axhline(y = 0, linestyle = '--')
plt.xlabel("バンド幅")
plt.ylabel("トリートメント効果の推定値")
plt.show()