import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import pandas as pd
import random第2章のPythonコード
第2章 統計の基礎知識
モジュールのインポート
乱数の設定
np.random.seed(seed = 2022)2.1 母集団と標本
np.random.normal(loc = 50, scale = 10, size = 100)array([49.99472101, 47.25098575, 48.60714438, 69.84686158, 52.82109326,
57.60808658, 53.00981606, 55.40297269, 53.73497287, 53.77813394,
49.09786807, 26.94056731, 61.42760024, 34.64345715, 41.36247982,
60.16544935, 60.33963883, 41.75507772, 50.18904856, 46.16656444,
46.95814525, 59.97291506, 48.72726159, 35.24114098, 30.59093671,
58.33648924, 44.32782112, 61.74486957, 53.19068832, 51.90870428,
53.69270181, 48.98852137, 40.58190511, 35.95858291, 70.80647012,
48.79683766, 57.59791879, 68.27432141, 43.39272913, 41.92193739,
58.87800115, 47.8255255 , 40.60475484, 55.99538317, 72.23112696,
60.0000546 , 61.49674543, 48.44423709, 33.49424145, 35.44885832,
53.20761591, 58.11349632, 47.59195403, 51.65121081, 49.66499426,
50.87864582, 60.3414653 , 39.3917344 , 39.86415542, 45.79767814,
59.32153253, 53.17323935, 40.57528751, 53.21267299, 36.30446271,
47.86831958, 48.85253735, 56.22369315, 55.55244296, 20.42567762,
42.59524401, 59.44580195, 60.97987999, 54.94958386, 62.61002145,
56.3515109 , 56.57400017, 42.19071988, 44.81091942, 42.17828291,
35.94194861, 43.48428529, 56.26517082, 45.25246813, 33.59101206,
45.52156272, 51.30390562, 58.83383156, 53.28057914, 43.63514543,
55.57485529, 57.5430655 , 38.8137017 , 53.27741381, 59.49796933,
43.94538564, 59.23245365, 46.62167668, 49.53154238, 40.43541804])x = np.linspace(0, 100, 1000)
plt.plot(x, stats.norm.pdf(x, 50, 10))
plt.show()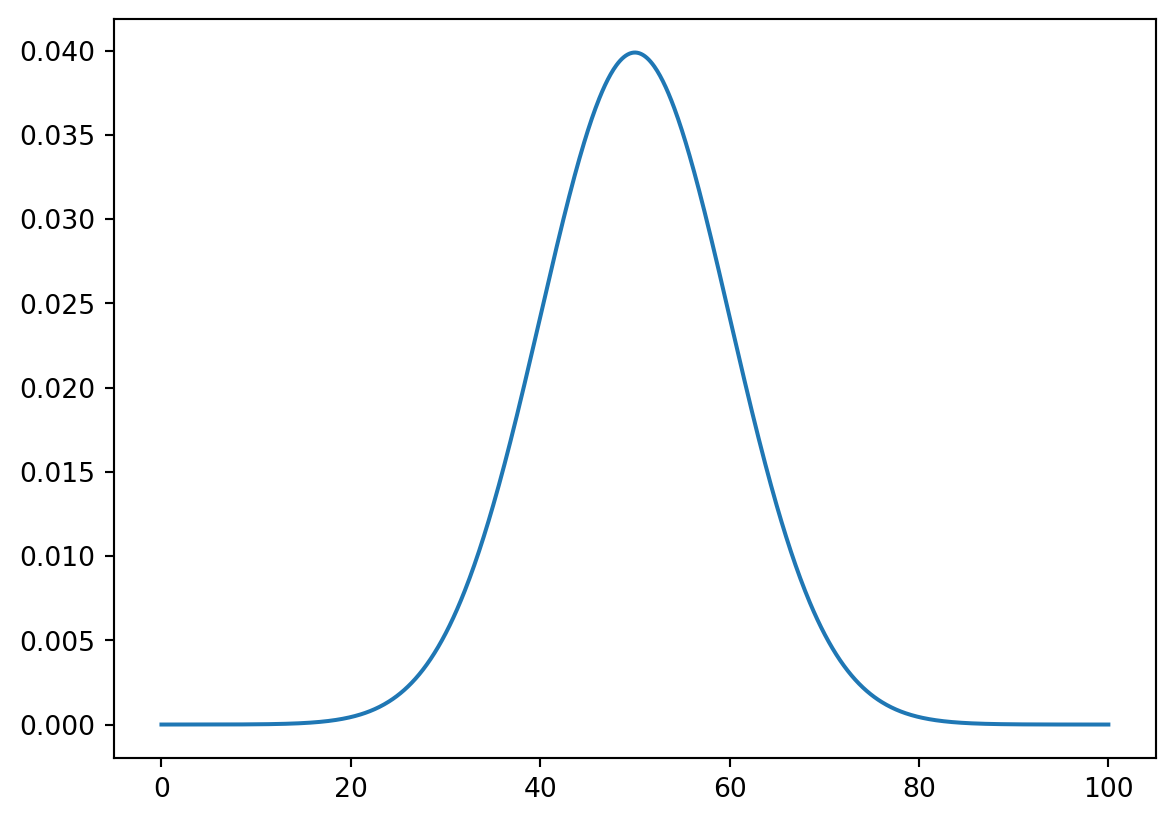
stats.norm.cdf(60, 50, 10)0.84134474606854292.2 無作為抽出
np.random.normal(loc = 50, scale = 10, size = 100)array([47.13103493, 33.58825656, 29.85508251, 46.19321417, 58.40700349,
39.34010904, 53.9253668 , 49.82916939, 55.7996853 , 51.7081044 ,
52.57465206, 48.25245403, 47.37792376, 35.07676005, 44.86325183,
53.02323255, 33.14964413, 68.1021357 , 47.68559183, 45.16370406,
37.89321109, 32.64646579, 40.75730075, 59.54163576, 61.29848363,
44.02887416, 43.24807054, 73.21689054, 65.82953229, 34.59470848,
64.46167673, 51.84274229, 52.14132825, 41.28526134, 37.46017619,
61.40699007, 52.01682162, 69.77840887, 50.06100905, 56.34177827,
57.0990048 , 39.19222004, 53.2832685 , 35.85552674, 55.25404022,
61.26085465, 55.63090958, 66.67681951, 55.08770271, 30.10780071,
55.80713169, 53.04220749, 56.20596989, 29.39941004, 52.59395198,
68.80963035, 47.15815106, 45.63649421, 51.84633014, 62.55909037,
48.9895312 , 43.44810305, 57.39128785, 44.49845598, 63.23308438,
46.50727411, 50.57981759, 50.91680296, 59.76947488, 50.11056925,
44.64912369, 55.17860478, 45.24275558, 38.89570647, 62.49072253,
64.74559596, 56.99177108, 57.67609186, 37.08592728, 44.43126163,
48.42429376, 56.0484774 , 30.59292404, 41.89940382, 53.51330912,
56.43490379, 40.68643864, 66.49845924, 54.4844567 , 52.45094516,
45.81927788, 57.7931036 , 37.07942698, 50.01473726, 58.37975889,
35.77893092, 43.29650892, 47.09256803, 54.98556885, 51.96929508])Z = np.random.normal(loc = 50, scale = 10, size = 100)
print(Z)[45.6132729 50.70624319 52.37352024 44.91631519 46.38945285 37.27809036
50.39942817 64.07221293 46.15332501 55.3886464 55.51491402 41.31486983
34.10364385 47.56555505 53.33935111 53.07267367 45.30760009 53.79184817
53.50077115 49.80431537 60.83619731 52.2007858 61.80977936 54.07174601
62.3089279 34.45611181 47.33432059 57.1704424 42.03397524 72.77873549
30.99931985 70.45632243 70.95410191 52.0423973 55.31465351 56.30743535
49.47630031 71.23383436 43.2078909 60.45586143 62.42494555 42.45886992
42.49212002 57.9441625 60.35972973 62.67023158 42.48875936 66.01998843
65.93906117 76.27367345 64.21806548 45.44913553 49.30737071 50.72488381
54.82967154 56.48436033 40.86647071 45.73690206 49.73219968 50.70906762
42.08633095 33.13443968 33.28413707 48.97861176 39.09747012 44.65719839
45.34698859 44.31217863 40.02426065 36.0709589 56.3597246 44.71088927
57.79383619 55.46594373 62.09410046 67.56890295 34.73599374 36.5066232
46.52949037 50.62702556 46.55179596 58.83098306 57.78559575 30.11975941
39.14943801 37.25391577 45.40526673 52.16828339 62.77142557 48.98604599
58.70885349 53.92198084 57.43345124 52.93054945 67.02913737 38.9488543
55.66727696 22.85327386 44.55533706 51.68791797]plt.hist(Z)
plt.show()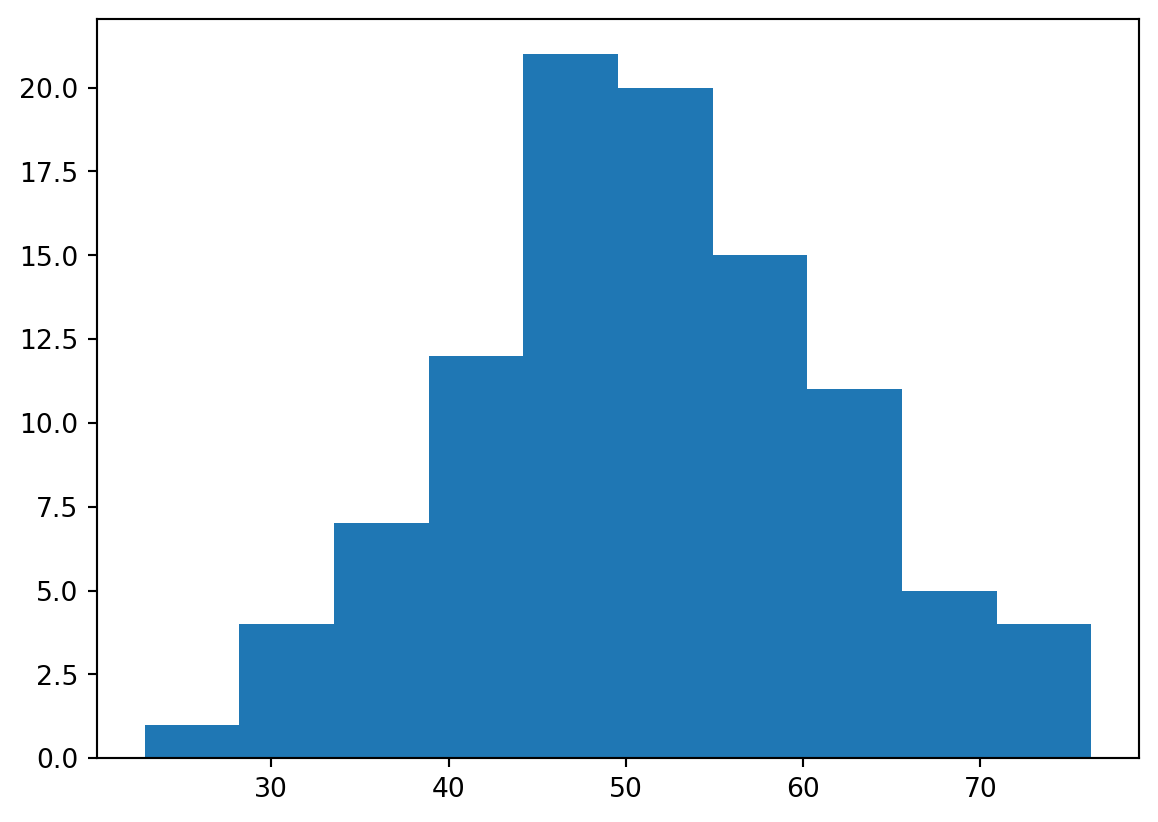
stats.norm.cdf(60, 50, 10)0.8413447460685429np.random.normal(loc = 50, scale = 10, size = 100)array([51.42425979, 53.5154309 , 58.47515057, 53.49860952, 24.82608009,
33.56206763, 45.88539849, 45.96384098, 48.58008251, 49.68454405,
41.95829213, 54.82443662, 37.63503971, 45.37340215, 54.02598511,
42.89584822, 30.9072515 , 33.28264684, 28.99870193, 30.38498867,
51.04346577, 37.87562203, 41.40861503, 44.7791151 , 49.06870718,
38.36307445, 45.94097145, 37.31623318, 59.13865982, 50.50201607,
55.48829572, 47.32171442, 47.0332455 , 50.45007027, 54.57863987,
55.42126518, 49.34598188, 42.26104496, 57.66945442, 39.67705044,
28.02696697, 52.06153471, 57.52759441, 56.20501762, 40.25307262,
74.29156672, 46.25761158, 49.68215298, 59.08353912, 56.25291019,
45.30089721, 54.7218065 , 50.79152467, 51.78364758, 43.25782769,
59.05447658, 48.77045606, 37.34158108, 54.15394664, 45.47136896,
52.81526183, 56.07048783, 37.67858057, 50.07143957, 42.81323084,
50.69354917, 54.19681523, 71.4612746 , 62.15299209, 43.3714096 ,
64.1685468 , 54.05450033, 60.99877937, 60.03118296, 41.96296007,
45.63634498, 39.75741125, 65.85807575, 45.78305451, 56.20859056,
48.38048567, 49.91257881, 32.92371827, 50.67458949, 44.43770795,
43.37283355, 53.19725905, 46.78557974, 43.43791716, 57.35538419,
48.20342139, 42.88380941, 52.47115239, 55.71769437, 41.75448621,
61.58053639, 66.08609974, 45.92657259, 46.60064707, 47.0446782 ])Z = np.random.normal(loc = 50, scale = 10, size = 100)
print(Z)[55.56308949 58.92594183 51.74410033 51.82493409 43.35088162 35.65460276
63.73217208 72.72946364 41.505615 47.72970046 37.55512591 38.98446711
46.98918598 43.78621054 72.693942 52.90513725 61.94704877 54.39662376
62.25949055 58.18614562 64.4505473 49.63677464 35.55754203 49.96803364
58.7491616 58.11357004 44.71216287 44.66591195 49.6389649 47.28876226
64.74385574 51.846617 64.15585876 48.86587171 66.41972457 32.12770359
44.04567526 45.24134448 48.98499164 46.17057193 56.40895847 48.1698655
33.26757501 59.15952125 58.52544425 43.31042397 46.05961588 42.83430693
60.45917126 71.32671274 59.56879825 57.87810855 50.99237268 54.13165975
44.58131297 55.48335682 59.51179458 51.13981499 61.30186816 58.02345502
69.53859981 29.37957849 60.24043987 28.42661121 50.08872668 40.93353225
57.55186841 65.72059903 43.09246207 55.14678501 62.39742119 57.17272244
57.57421919 51.26579461 29.26141169 47.20565961 72.76855106 44.46087536
53.81184786 44.62383405 37.96568413 42.48113148 45.16490987 46.52200384
65.41681771 45.05473113 31.85306954 54.01869239 41.49209705 45.3697207
58.80160505 21.59211869 43.9393657 50.9861717 44.88589469 68.26768422
48.55745435 45.50947446 31.84303288 39.53414932]plt.hist(Z)
plt.show()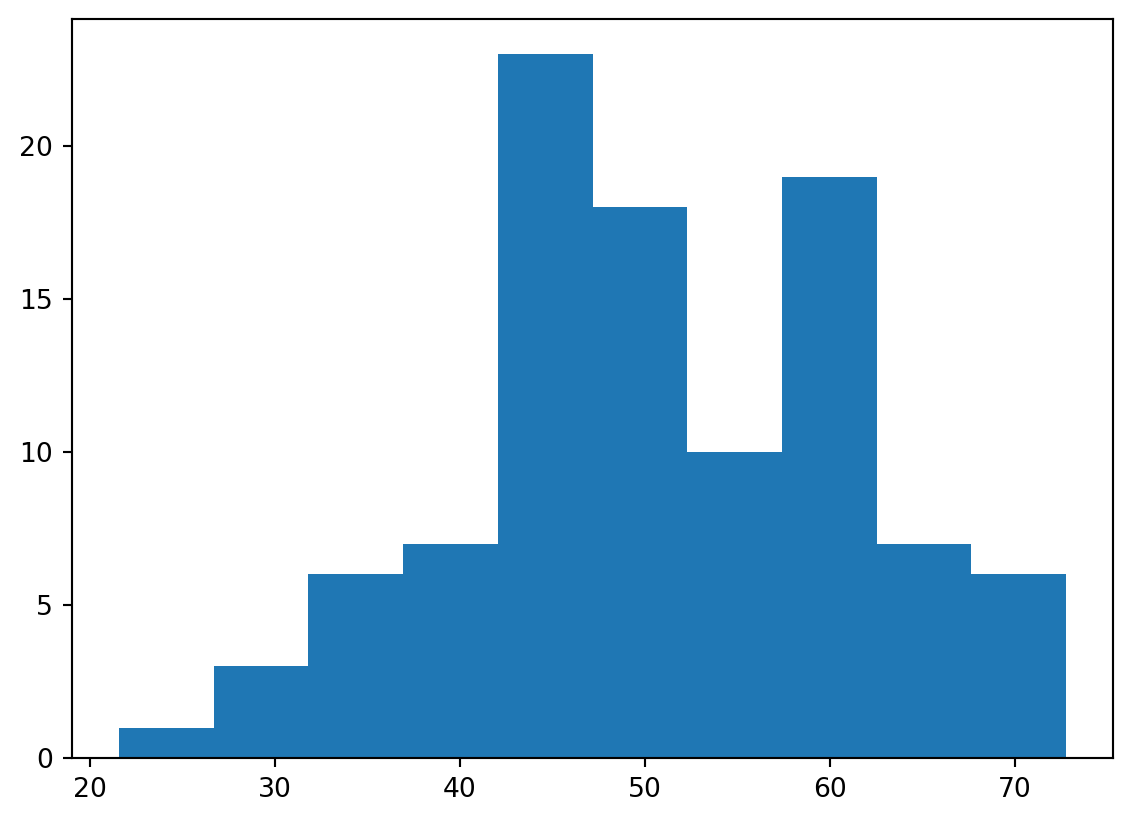
print(Z[0:9])[55.56308949 58.92594183 51.74410033 51.82493409 43.35088162 35.65460276
63.73217208 72.72946364 41.505615 ]a = [4, 9, 99]
print(a)[4, 9, 99]print(Z[a])[43.35088162 47.72970046 39.53414932]print(Z[[4, 9, 99]])[43.35088162 47.72970046 39.53414932]print(Z.max())72.7685510582825print(Z.argmax())76print(Z.min())21.59211869077521print(Z.argmin())91print(Z.mean())50.6989901053187pd.DataFrame(Z).describe()| 0 | |
|---|---|
| count | 100.000000 |
| mean | 50.698990 |
| std | 10.788310 |
| min | 21.592119 |
| 25% | 44.357075 |
| 50% | 50.028380 |
| 75% | 58.581374 |
| max | 72.768551 |
print(np.random.choice(list(range(1, 11)), size = 3, replace = False))[6 1 9]print(np.random.choice(Z, size = 5, replace = False))[68.26768422 51.26579461 46.17057193 48.55745435 44.88589469]fruits = ['ミカン', 'バナナ', 'リンゴ', 'レモン', 'モモ']
print(np.random.choice(fruits, size = 1, replace = False))['ミカン']print(np.random.choice(fruits, size = 2, replace = False))['バナナ' 'リンゴ']coin = ['Head', 'Tail']
print(np.random.choice(coin, size = 5, replace = True))['Head' 'Head' 'Tail' 'Tail' 'Tail']2.3 平均と大数の法則
print(np.random.normal(loc = 50, scale = 10, size = 100).mean())49.512357635821026S = 1000
rec = np.zeros(S)
for i in range(S):
rec[i] = np.random.normal(loc = 50, scale = 10, size = 100).mean()
print(np.zeros(10))[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]pd.DataFrame(rec, columns = ["rec"]).describe()| rec | |
|---|---|
| count | 1000.000000 |
| mean | 50.052719 |
| std | 1.004157 |
| min | 46.693355 |
| 25% | 49.374049 |
| 50% | 50.051283 |
| 75% | 50.713553 |
| max | 53.299470 |
for i in range(S):
rec[i] = np.random.normal(loc = 50, scale = 10, size = 10000).mean()
pd.DataFrame(rec, columns = ["rec"]).describe()| rec | |
|---|---|
| count | 1000.000000 |
| mean | 50.003471 |
| std | 0.100352 |
| min | 49.638529 |
| 25% | 49.934342 |
| 50% | 50.000796 |
| 75% | 50.067496 |
| max | 50.316880 |
np.random.choice(list(range(1, 7)), size = 10, replace = True).mean()3.4```{python}S = 1000} rec = np.zeros(S)
for i in range(S): rec[i] = np.random.choice(list(range(1, 7)), size = 10, replace = True).mean()
pd.DataFrame(rec, columns = [“rec”]).describe()
::: {.cell execution_count=33}
``` {.python .cell-code}
S = 1000
rec = np.zeros(S)
for i in range(S):
rec[i] = np.random.choice(list(range(1, 7)), size = 1000, replace = True).mean()
pd.DataFrame(rec, columns = ["rec"]).describe()| rec | |
|---|---|
| count | 1000.000000 |
| mean | 3.497679 |
| std | 0.053496 |
| min | 3.318000 |
| 25% | 3.460000 |
| 50% | 3.499000 |
| 75% | 3.536250 |
| max | 3.651000 |
:::
S = 1000
rec = np.zeros(S)
for i in range(S):
rec[i] = np.random.choice(list(range(1, 7)), size = 10000, replace = True).mean()
pd.DataFrame(rec, columns = ["rec"]).describe()| rec | |
|---|---|
| count | 1000.000000 |
| mean | 3.499508 |
| std | 0.017518 |
| min | 3.442800 |
| 25% | 3.487075 |
| 50% | 3.499700 |
| 75% | 3.511525 |
| max | 3.551300 |
2.4 分散と標準偏差
x = np.random.normal(loc = 50, scale = 10, size = 1000)
x.var()102.28530619602545x.std()10.113619836439643S = 1000
n = 1000
rec = np.zeros(S)
for i in range(S):
rec[i] = np.random.normal(loc = 50, scale = 10, size = n).std()
pd.DataFrame(rec, columns = ["rec"]).describe()| rec | |
|---|---|
| count | 1000.000000 |
| mean | 9.994303 |
| std | 0.217617 |
| min | 9.278687 |
| 25% | 9.856020 |
| 50% | 9.987452 |
| 75% | 10.140075 |
| max | 10.587572 |
2.5 相関係数と共分散
np.random.seed(seed = 2022) # 乱数の再設定
x = np.random.normal(loc = 50, scale = 10, size = 100)
y = np.random.normal(loc = 50, scale = 10, size = 100)
plt.scatter(x, y)
plt.show()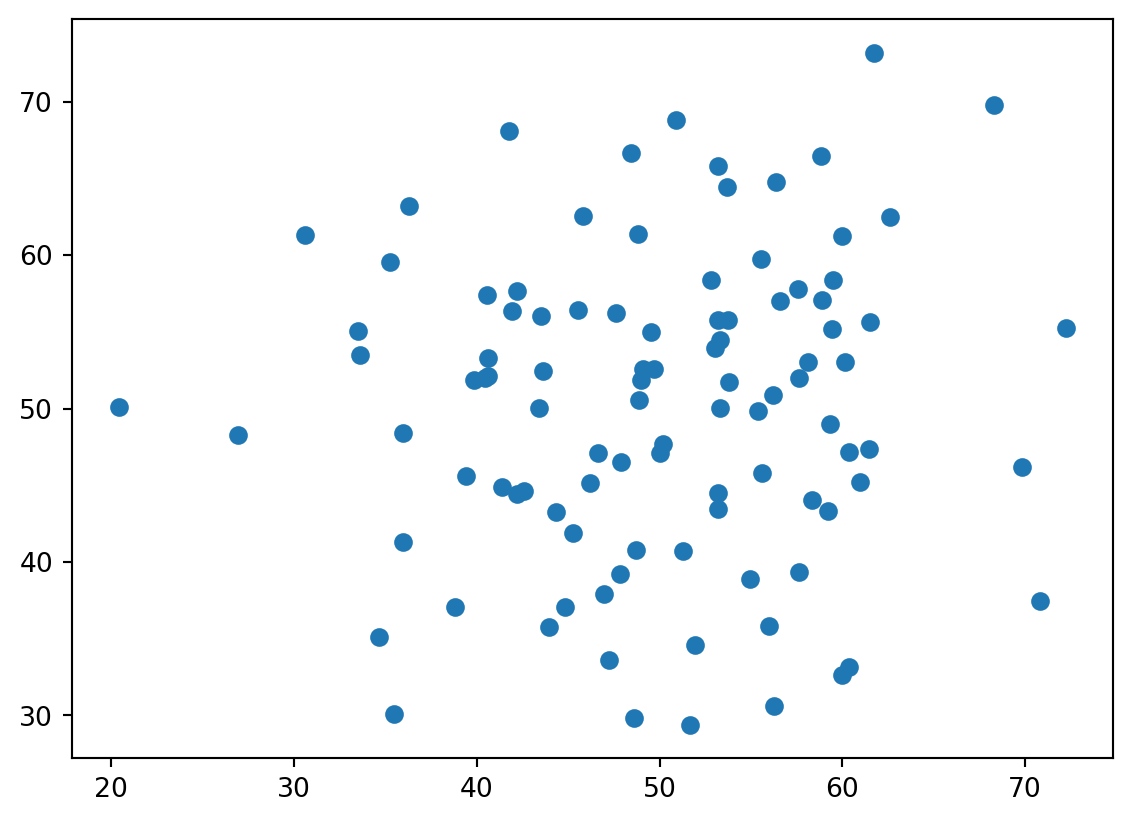
z = (x + y) / 2
plt.scatter(x, z)
plt.show()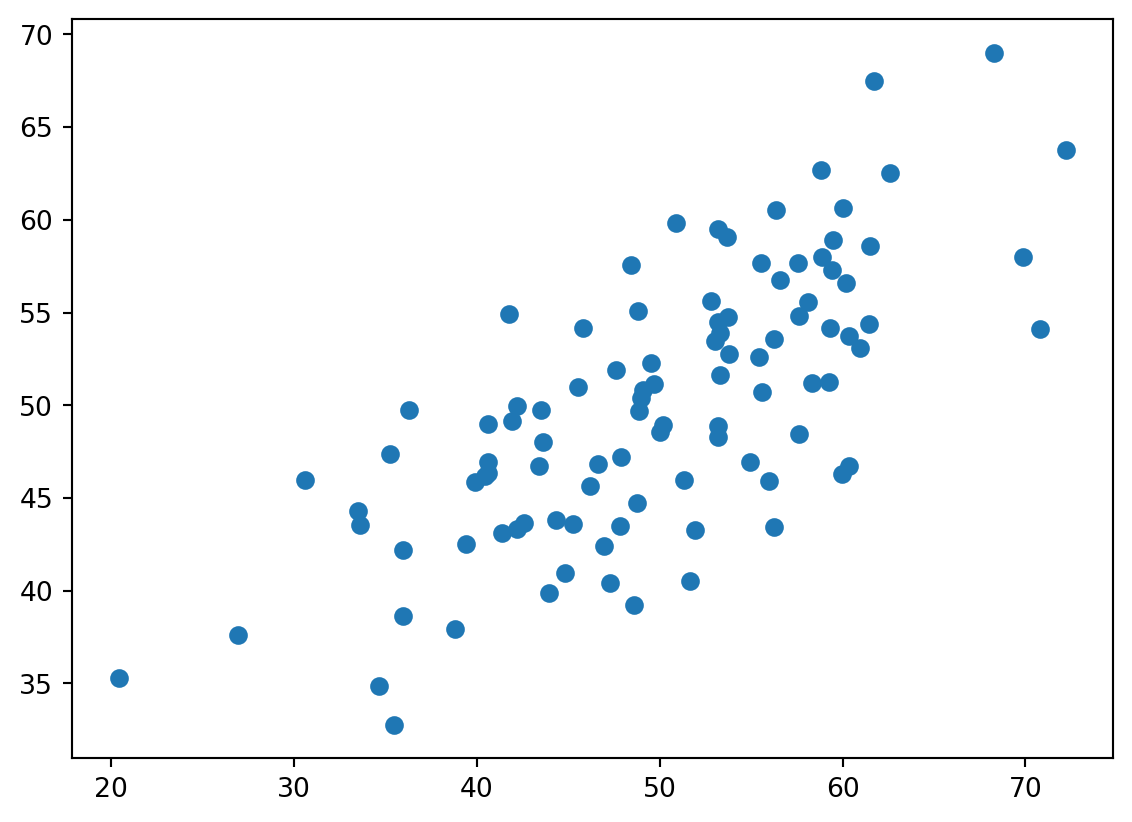
print(np.corrcoef(x, y))[[1. 0.0739499]
[0.0739499 1. ]]print(np.corrcoef(x, z))[[1. 0.72036288]
[0.72036288 1. ]]print(np.cov(x, y))[[92.09382748 7.08084781]
[ 7.08084781 99.55539077]]