第8章のStataコード
第8章 ランダム化実験
8.1 授業の出席率と成績:セレクションバイアス
8.1.1 因果関係?単なる相関関係?
import delimited "class_attendance.csv", clear case(preserve)
twoway scatter Y D, jitter(20) jitterseed(2022) xscale(range(-0.5, 1.5)) xlabel(0(1)1)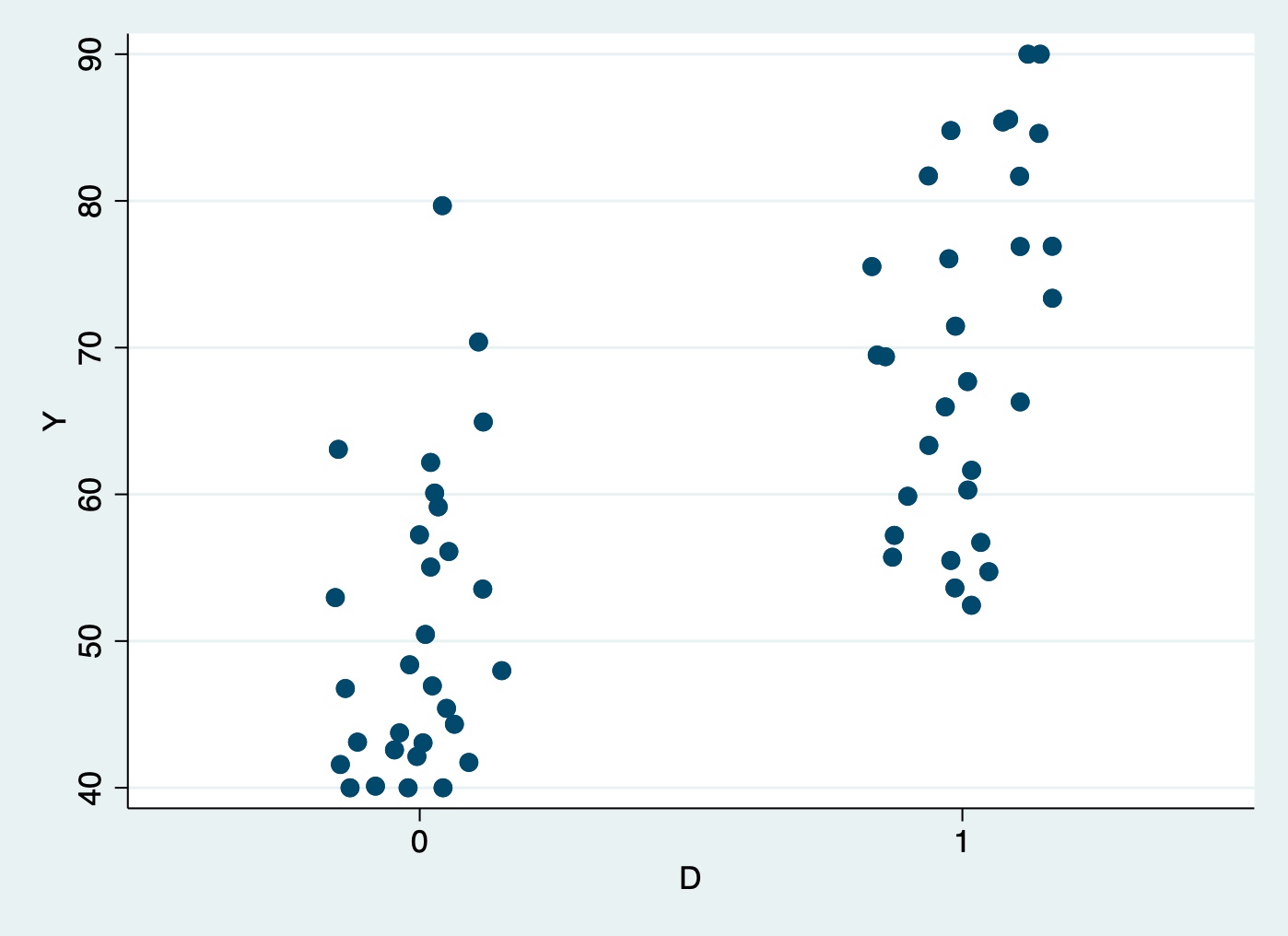
collapse (count) 学生数 = Y (mean) 平均点 = Y (min) 最低点 = Y (max) 最高点 = Y, by(D)
label define labelD 0 "D = 0 (出席率50%未満)" 1 "D = 1 (出席率50%以上)"
label values D labelD
gsort -D
list, noobs +------------------------------------------------------------+
| D 学生数 平均点 最低点 最高点 |
|------------------------------------------------------------|
| D = 1 (出席率50%以上) 30 69.8333 53 90 |
| D = 0 (出席率50%未満) 30 50.7333 40 78 |
+------------------------------------------------------------+8.2 ランダム化実験
8.2.2 セレクションバイアスの除去
import delimited "class_attendance.csv", clear case(preserve)
regress Y D Source | SS df MS Number of obs = 60
-------------+---------------------------------- F(1, 58) = 48.84
Model | 5472.15 1 5472.15 Prob > F = 0.0000
Residual | 6498.03333 58 112.035057 R-squared = 0.4571
-------------+---------------------------------- Adj R-squared = 0.4478
Total | 11970.1833 59 202.884463 Root MSE = 10.585
------------------------------------------------------------------------------
Y | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
D | 19.1 2.732948 6.99 0.000 13.62941 24.57059
_cons | 50.73333 1.932486 26.25 0.000 46.86504 54.60162
------------------------------------------------------------------------------